Afinal o que é Ciência de dados? Já faz um tempo que essa área ganhou grande notoriedade e a atenção de muitas empresas. A demanda por profissionais cresceu enormemente, e como consequência as dúvidas sobre Ciência de Dados aumenta de forma exponencial.
Este post tenta responder essa pergunta descrevendo de uma forma sucinta o que é Ciência de dados, discorre sobre a sua matéria-prima - os dados - e comenta um pouco sobre os principais profissionais envolvidos nessa área.
Definição
Ciência de dados é uma área que congrega várias disciplinas, dentre as quais pode-se citar estatística, matemática, computação entre outras. Possui como objetivo principal adquirir conhecimento através da análise de uma grande quantidade de dados.
Para adquirir esse conhecimento é necessário vários processos que vão desde a aquisição desses dados em sua fonte de origem (planilhas, banco de dados, xml, csv, videos, imagens etc.), passando por sua limpeza até a posterior análise desses dados.
História
A Ciência de dados, como área, foi primeiramente descrita por William S. Cleveland, um cientista da computação e professor de Estatística da Purdue University.
Ele escreveu um artigo entitulado Data Science: An Action Plan for Expanding the Technical Areas of the Field of Statistics. Nesse paper William S. Cleveland combina o poder da computação com Data Mining para melhorar análises estatísticas.
Apartir desse momento o termo se expandiu e atualmente é amplamente utilizado para se referir a área responsável por analisar a grande quantidade de dados que geramos diariamente e retirar algum conhecimento deles.
Dados
Dados são fatos coletados e normalmente armazenados. Informação é o dado analisado e com algum significado. O conhecimento é a informação interpretada, entendida e aplicada para um fim.
-- Introdução à Ciência de Dados
O que é um dado?
Em termos gerais dados são características qualitativas (não mensuráveis) e quantitativas (mensuráveis) de um objeto ou pessoa.
Essas características estão armazenadas, na grande maioria das vezes, em banco de dados. Pode-se destacar os seguintes tipos de dados: estruturados, semi-estruturados e não-estruturados. A definição de cada um deles é descrita na seção abaixo.
Tipos de dados
Dados estruturados
Esses tipos de dados são organizados e estruturados em tabelas (linhas e colunas). Pode-se encontrá-los em base de dados relacionais ou planilhas eletrônicas.
Dados semi-estruturados
São dados que não podem ser armazenados em um banco de dados, mas possuem algum tipo de hierarquia e/ou ordem interna. Pode-se citar o xml e json.
Dados não-estruturados
Normalmente são dados que não possuem uma estrutura conhecida, ou seja, não se pode armazená-los em tabelas, como por exemplo, videos, músicas, emails etc.
Ciclo de vida
Atualmente os dados podem ser produzidos digitalmente de muitas formas por algum dispositivo, por exemplo, computadores, sensores, cameras digitais, eletrodomésticos etc.
Esses dados precisam ser armazenados em alguma estrutura, na maioria das vezes em um banco de dados, para que sejam consumidos posteriormente.
Para que os dados armazenados possam ser analisados é necessário que eles sofram um processo de transformação, que é possibilitar que esse dado fique em um formato acessível e com qualidade de análise.
Essa transformação é feita utilizando o processo de ETL (Extract, Transform and Load), em português Extrair, Transformar e Carregar. Normalmente os dados são carregados em Data Warehouses ou Armazém de dados desenvolvidos para facilitar a análise dos dados.
Depois que os dados passaram pelo processo de ETL podemos iniciar o processo de análise. Nesse momento começa a geração de informação e conhecimento a partir dos dados. É o momento de lapidá-los.
Por fim em sua última etapa os dados podem ser descartados. Pode-se estipular um tempo para seu armazenamento. Isso varia conforme políticas de gestão de dados da organização.

Ciclo de vida do dado
Big data
Big data é um termo genérico para qualquer coleção de dados tão grandes ou complexos, que fica difícil processá-los usando técnicas tradicionais de gerenciamento de dados convencional. Pode-se ter uma variedade de dados gerados de inúmeras formas.
Para gerenciar e trabalhar com essa grande quantidade de dados, Big Data engloba outros conceitos e tecnologias como computação em nuvem, estatística, infraestrutura, governança de dados e de projetos etc. Na grande maioria das vezes em projeto de Ciência de Dados utiliza-se Big Data como aliada no gerenciamento e análise de dados coletados.
Inicialmente o conceito de Big Data foi proposto utilizando apenas 3 V’s: volume, velocidade e variedade. Foram acrescentados mais 2: veracidade e valor. Essa lista de V’s está em constante crescimento e pode-se encontrar até mais de 10 V’s 😱. Aqui serão abordados apenas 5 V’s, que serão descritos na seção seguinte.
Os 5 V’s do Big Data
- Volume
Descreve a quantidade de dados armazenados por uma organização. Lembrando que os esforços de armazenamento, análise e gestão de dados aumentam conforme crescem a geração dos dados.
- Velocidade
Corresponde a velocidade de processamento e disponibilização dos dados para análise.
- Variedade
Os dados podem aparecer em diversos formatos e vir de diferentes fontes.
- Veracidade
Esse item se refere a qualidade e confiança dos dados.
- Valor
Quando os dados coletados e analisados geram valor para a organização.
Processo da Ciência de dados
Na Ciência de Dados existe um processo bem definido que se inicia na coleta dos dados até a visualização dos mesmos. Os próximos items explicarão cada fase individualmente.
Coleta dos dados
Nesta fase sabe-se quais dados são necessários e onde se pode encontrá-los. Eles podem estar em vários locais, em APIs ou banco de dados, por exemplo, e de várias formas como tabelas, planilhas eletrônicas, xml, csv etc.
Preparação dos dados
Na fase anterior podem ocorrer erros ao efetuar a coleta dos dados. Nessa fase é o momento de corrigí-los, o que confere mais qualidade aos dados e os prepara para uso nas fases posteriores.
Essa fase consiste em três sub-fases: a limpeza de dados que remove valores falsos e inconsistências de uma fonte de dados; a integração de dados que enriquece os dados combinando informações de várias fontes; e a transformação de dados que garante que os dados estejam em um formato adequado para usar nas análises.
Exploração dos dados
A exploração de dados se preocupa em construir uma compreensão mais profunda dos dados. Tenta entender como as variáveis interagem umas com as outras, a distribuição dos dados e se existem discrepâncias.
Para conseguir isso, é necessário o uso principalmente de estatística, técnicas visuais e modelagem simples. Essa etapa geralmente é chamada de Análise Exploratória de Dados.
Inicia-se aqui o detalhamento dos tipos de dados com os quais estamos lidando. Esta é uma etapa essencial do processo.
Depois que essa etapa é concluída, o analista geralmente passa várias horas aprendendo sobre o domínio, usando código ou outras ferramentas para manipular e explorar os dados.
Modelagem dos dados
Nesta fase o uso intensivo de modelos de simulação e estatística utilizando machine learning é muito grande.
Esses modelos são desenvolvidos principalmente para prever situações ou cenários que são importantes para análise do negócio.
Visualização dos dados
Esta é a última fase do processo onde é apresentado o resultado para o time de negócios. Esses resultados podem ser visualizados de várias formas que podem variar de simples gráficos até aprimorados dashboards.
Mercado de trabalho
No início da Ciência de dados todo o processo de coleta, análise e visualização de dados era realizado pelo cientista de dados. Com o crescimento da área outras funções foram criadas, e cada profissional se especializou em algumas etapas do processo.
Hoje podemos destacar as 3 principais funções: Analista de Dados, Cientista de Dados e Pessoa Engenheira de dados. Cada uma dessas especializações possuem skills e focos específicos. No meu caso, em particular, me identifiquei com a área de Engenharia de Dados. 😃
Como se pode visualizar, no infográfico abaixo, cada área possui conhecimentos específicos. Esses são somente alguns dos skills necessários.
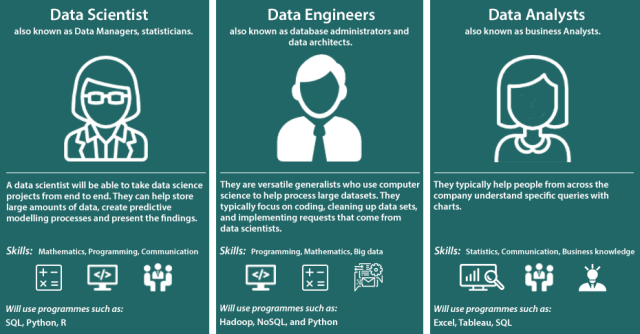
Analista de dados
O analista de dados organiza e interpreta os dados usando ferramentas de análise de dados. O resultado pode ser visualizado em forma de dashboards que servirão de guia para a tomada de decisão.
Alguns skills e ferramentas necessárias: SQL, R, Python, Ferramentas para visualização de dados (Tableau, Looker, Qlik View etc) e Estatística.
Cientista de dados
O cientista de dados extrai conhecimento e interpreta os dados, usando para isso muita estatística, matemática e algoritmos de machine learning.
Alguns skills e ferramentas necessárias: SQL, R, Python, Estatística, Machine Learning, NLP e Matemática e Modelagem.
Pessoa Engenheira de dados
O Pessoa Engenheira de dados possui como missão desenvolver meios de coletar, extrair, limpar e proteger os dados, entregando-os aos Cientistas e Analistas de dados para posterior análise.
Alguns skills e ferramentas necessárias: SQL\NoSQL, Python-Java-Scala (Pelo menos uma delas), Hadoop, Spark, Ferramentas de orquestração de tarefas ( Luigi, Airflow etc.), DW, ETL\ELT, Datalake, computação em nuvem (AWS-GCP-Azure - Pelo menos uma delas) e conhecimento de práticas de Engenharia de Software.
Links interessantes
Data Scientist: The Sexiest Job of the 21st Century
Data engineer: The ‘real’ sexiest job of the 21st century
Become a data scientist? or a data analyst? Here’s the difference
NoSQL e a Importância da Engenharia de Software e da Engenharia de Dados para o Big Data
Careers in Data Science: Data Analyst vs Data Engineer vs Data Scientist
Livros